本次的笔记主要记录了集合的底层实现原理的基本概念。先总结了List集合中的ArrayList集合和LinkedList集合的底层数据结构实现和源码分析。
一、集合的分类
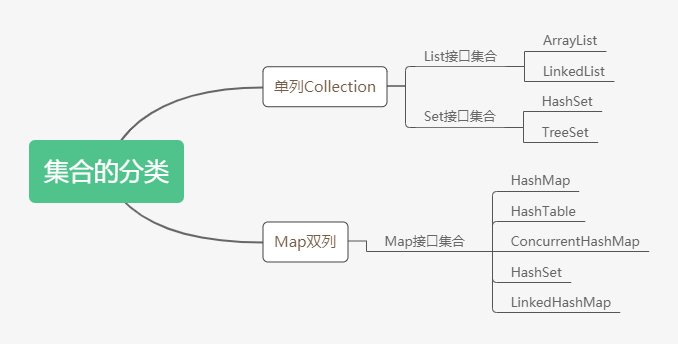
二、集合的基本概念
1、Collection单列集合概述
(1)是单列集合的顶层接口,他表示 一组对象,这些对象也成为Collection的元素。
(2)JDK不提供此接口的任何直接实现,他提供更具体的子接口(如set和list)实现。
2、Map双列集合概述
(1)将键映射到值的对象,不包含重复的键,每个键可以映射到最多一个值。
三、集合底层详解
1、ArrayList集合详解
1.1 基本概念
ArrayList是List接口的可变数组非同步实现,底层使用数组保存所有元素。其操作基本上是对数组的操作。
1
| private transient Object[] elementData;
|
该集合是可变长度的数组,数组扩容时,会将老数组中的元素拷贝一份到新数组中!每次数组扩容的大小是原容量的1.5倍。
1
2
3
4
5
6
7
8
9
10
| private void grow(int minCapacity) {
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
|
1.2 源码分析
1.2.1 类的继承关系
ArrayList继承AbstractList抽象父类。实现了List接口。RandomAccess(可随机访问)、Cloneable(可拷贝)、Serializable (可序列化)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
private static final long serialVersionUID = 8683452581122892189L;
private static final int DEFAULT_CAPACITY = 10;
private static final Object[] EMPTY_ELEMENTDATA = {};
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
transient Object[] elementData;
private int size;
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
}
|
1.2.2 ArrayList类的构造器
1.2.2.1 ArrayList(int)型构造函数
1
2
3
4
5
6
7
8
9
| public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+ initialCapacity);
}
}
|
1.2.2.2 ArrayList()型构造函数
1
2
3
4
| public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
|
1.2.2.3 ArrayList(Collection<? extends E>)型构造函数
1
2
3
4
5
6
7
8
9
| public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
this.elementData = EMPTY_ELEMENTDATA;
}
}
|
1.2.3 常用核心方法分析
1.2.3.1 add函数:向数组中添加元素
1
2
3
4
5
| public boolean add(E e) {
ensureCapacityInternal(size + 1);
elementData[size++] = e;
return true;
}
|
ensureCapacityInternal此函数可以理解为确保elementData数组有合适的大小。
ensureCapacityInternal方法的实现方法如下。
1
2
3
4
5
6
7
| private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
|
ensureExplicitCapacity函数也是为了确保elemenData数组有合适的大小。ensureExplicitCapacity的具体函数如下
1
2
3
4
5
6
| private void ensureExplicitCapacity(int minCapacity) {
modCount++;
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
|
最后又调用了grow()方法,该方法才是真正扩容数组的方法,正常情况下会扩容1.5倍。特殊情况下(新的数组大小已经达到最大值)则只取最大值。
1.2.3.2 set函数:通过下标索引设置相应位置处的值
1
2
3
4
5
6
7
8
9
10
| public E set(int index, E element) {
rangeCheck(index);
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
}
|
1.2.3.3 indexOf函数:从首开始查找数组里面是否存在指定元素
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
|
从头开始查找与指定元素相等的元素,注意,是可以查找null元素的,意味着ArrayList中可以存放null元素的。与此函数对应的lastIndexOf,表示从尾部开始查找。
1.2.3.4 get函数:通过下标索引获取相应位置处的值
1
2
3
4
5
6
| public E get(int index) {
rangeCheck(index);
return elementData(index);
}
|
get函数会检查索引值是否合法(只检查是否大于size,而没有检查是否小于0),值得注意的是,在get函数中存在element函数,element函数用于返回具体的元素,具体函数如下
1
2
3
| E elementData(int index) {
return (E) elementData[index];
}
|
返回的值都经过了向下转型(Object -> E),这些是对我们应用程序屏蔽的小细节。
1.2.3.5 remove函数:通过下表索引删除数组中相应位置的值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null;
return oldValue;
}
|
1.3 ArrayList总结
ArrayList由于底层是数组实现的,所以相较于LinkedList,ArrayList集合查询、修改速度快,但是在指定位置删除和添加元素时由于需要移动指定位置之后的元素所以速度相比较慢。
2、LinkedList集合详解
2.1 基本概念
LinkedList底层的数据结构是双向循环链表,头结点不存放元素
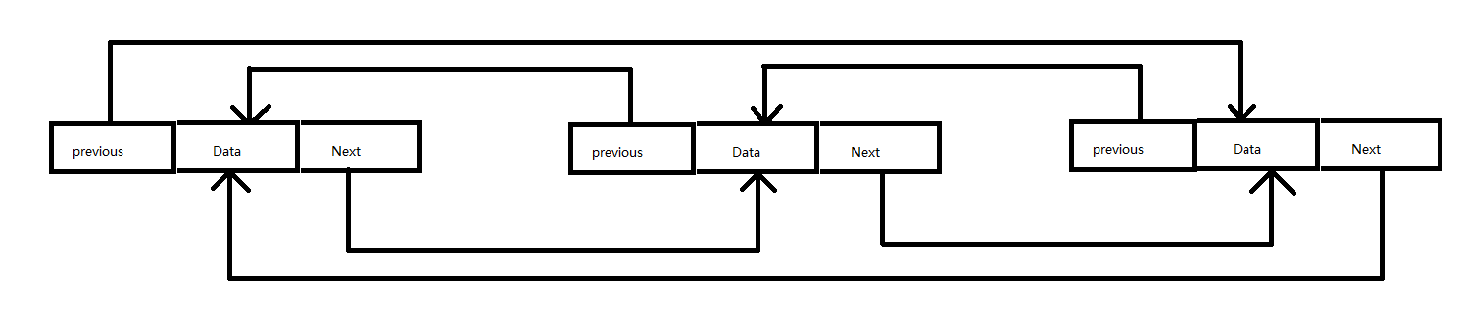
2.2 源码分析
2.2.1 类的继承关系
1
2
| public class LinkedList<E> extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
|
LinkedList 是一个继承于AbstractSequentialList的双向链表。它也可以被当作堆栈、队列或双端队列进行操作。
LinkedList 实现 List 接口,能对它进行队列操作。
LinkedList 实现 Deque 接口,即能将LinkedList当作双端队列使用。
LinkedList 实现了Cloneable接口,即覆盖了函数clone(),能克隆。
LinkedList 实现java.io.Serializable接口,这意味着LinkedList支持序列化,能通过序列化去传输。
LinkedList 是非同步的。
2.2.2 内部类(结点类)
1
2
3
4
5
6
7
8
9
10
11
12
| private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
|
用于构建链表的组成对象(结点)
2.2.3 LinkedList的属性
1
2
3
4
5
6
7
8
9
10
11
| public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
transient int size = 0;
transient Node<E> first;
transient Node<E> last;
}
|
2.2.4 LinkedList的构造器
2.2.4.1 LinkedList()型构造函数
创建一个空的头结点。
2.2.4.2 LinkedList(Collection<? extends E>)型构造函数
1
2
3
4
5
6
| public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
|
这个构造方法的参数是一个集合,可以将这个集合中的所有元素信息存入双向链表。
2.2.5 常用核心方法分析
2.2.5.1 add函数:向链表的末尾添加进一个结点对象
1
2
3
4
5
| public boolean add(E e) {
linkLast(e);
return true;
}
|
该方法添加到末尾的具体逻辑是由linkLast函数完成,linkLast方法的具体实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
|
2.2.5.2 addAll函数
addAll有两个重载函数,addAll(Collection<? extends E>)型和addAll(int, Collection<? extends E>)型,我们平时习惯调用的addAll(Collection<? extends E>)型会转化为addAll(int, Collection<? extends E>)型,所以着重分析此函数即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
public boolean addAll(int index, Collection<? extends E> c) {
checkPositionIndex(index);
Object[] a = c.toArray();
int numNew = a.length;
if (numNew == 0)
return false;
Node<E> pred, succ;
if (index == size) {
succ = null;
pred = last;
} else {
succ = node(index);
pred = succ.prev;
}
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
Node<E> newNode = new Node<>(pred, e, null);
if (pred == null)
first = newNode;
else
pred.next = newNode;
pred = newNode;
}
if (succ == null) {
last = pred;
} else {
pred.next = succ;
succ.prev = pred;
}
size += numNew;
modCount++;
return true;
}
|
参数中的index表示在索引下标为index的结点(实际上是第index + 1个结点)的前面插入。在addAll函数中,addAll函数中还会调用到node函数,get函数也会调用到node函数,此函数是根据索引下标找到该结点并返回,具体代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| Node<E> node(int index) {
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
|
2.2.5.3 unlink函数
在调用remove移除结点时,会调用到unlink函数(将指定的结点从链表中断开,不再累赘),unlink函数具体如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| E unlink(Node<E> x) {
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
|
2.3 LinkedList总结
LinkedList的底层数据结构是循环双向链表,但由于实现了多个接口所以当需要使用栈、队列等操作时,可以考虑该结构。
ArrayList参考文献:
[https://www.cnblogs.com/leesf456/p/5308358.html]:
LinkedList参考文献:
[[](https://www.cnblogs.com/leesf456/p/5308843.html)]:
[[](https://www.cnblogs.com/ITtangtang/p/3948610.html#a4)]:



